
1. Discriminative Model
데이터 X가 주어졌을 때 레이블 Y가 나타날 조건부 확률 p(Y|X)를 직접적으로 반환하는 모델이다. 레이블 정보가 있어야 하기 때문에 지도학습이며 X의 레이블을 잘 구분하는 결정경계(decision boundary)를 학습하는 것이 목표가 된다. 가정이 단순하고 학습데이터의 양이 충분하면 좋은 성능을 내게 된다. linear, logistic regression은 discriminative model의 예시이다.
2. Generative Model
p(x)의 분포를 배운다! 여기에서 x는 데이터를 의미하고 모든 가능한 image들에 대해 분포를 학습하게 된다. 특정 이미지가 존재할 확률을 할당하는데, 이미지의 그럴 듯한 정도에 따라서 확률을 부여하는 것이겠지? 이때 합리적으로 확률을 할당하려면 이미지에 대한 깊은 이해가 필요하겠다. 이 때 모델은 discriminate의 단점을 해결하게 되는데, discriminate model에서 label list에 없는 label을 가진 이미지가 들어왔을 때도 모든 label에 대한 분포를 내뿜어야 했었다. 하지만 generative model은 비합리적인 이미지에 대해 굉장히 낮은 확률을 부여해서 틀린 이미지라고 말할 수 있다.
이 모델은 먼저 데이터의 특징을 학습하고 이때 학습을 잘 하면 생성도 잘 할 것이고, train때 분포로 학습한 것에서 샘플링하는 과정을 거치게 된다.
데이터의 분포를 학습한다고 하는데,, 데이터의 분포가 무엇인가 하면 밑에 그래프가 사람 얼굴 사진에 관한 그래프라고 가정하자. 이때 동양인의 얼굴이면 검은색 머리에 황인종의 분포가 가장 많을 것이다. 이러한 분포를 의미하게 된다.


데이터의 분포를 근사하는 모델
3. Conditinal Generative Model
이는 p(x|y)를 배우는 조건부 생성 모델이다. 각 클래스 별로 가지는 conditional density와 각 클래스의 prior distribution을 이용하여 데이터와 class의 joint probability를 모델링하고 새로운 데이터가 어떤 class에 들어가야 하는지 결정을 내려서 output y를 계산하는 것이다. 여기에서도 outlier을 reject하는 방법?? label이 주어졌을 때 이미지를 생성했다고 했을 때 특정 이미지가 어떠한 레이블에서도 낮은 확률을 가진다고 하면 이는 분류할 수 없다고 말하는 것이다.
여기에서 학습하는 것은 범주의 분포를 학습하는 것이 목표이다. 이는 bayes' rule을 사용하는데, discriminative model은 이미지에서 label판별하는 것이고 generative model은 이미지를 생성하는 것인데 직접 계산하지 못한다. 흠.. prior over labels는 레이블에 대한 사전분포인데 주어진 입력에 대한 각 클래스의 확률을 추론하는 것이다.

자 여기에서 Generative Model에 관한 그래프를 살펴보겠다!

맨 위에 Generative models있고 generative model은 이미지에 밀도함수를 할당하는 것이고, 이미지에 대한 밀도함수 p(x)를 직접적으로 계산할 수 있는 Explicit density와 직접적으로 계산할 수 없어서 p(x)가 큰 값을 가지는 것에서 샘플링하는 Implicit density가 있다.
먼저 Explicit density에서 Tractable density는 학습 데이터의 분포를 학습하기 위해서 연쇄법칙을 통해 직접 구할 수 있고, 이는 이전 픽셀들의 값을 통해서 현재 픽셀의 값을 결정하겠다는 것이다. 이때의 장점은 확률이 명확하기 때문에 생성되는 이미지도 뚜렷하고 단점으로 순서 자체를 학습했기 때문에 속도의 측면에서 느리다.
다음은 Approximate density인데 이는 p(x)를 대애략 계산할 수 있다. 여기에서 Variational이랑 Markov Chain이 있다. Variational은 복잡한 확률 분포를 직접 모델링하기 어려울 때 다른 방식으로 분포를 근사하는 방식이다.
Markov Chain은 샘플링을 통해 주어진 확률 분포로부터 샘플을 추출하는 방법이다. 흠...
다음은 Implicit density에 관해서 Markov Chain과 Direct에 대해서 정리해보겠다.
Markov Chain은 샘플링 한 값에서 주어진 확률 분포로부터 샘플을 추출하는 방식이다.
Direct는 샘플링을 한 값을 그대로 갖다 모델에 쓰는 것이라고 한다.
다음은 Explicit Density Estimation에 대해 설명해보겠다.

여기에서 맨 마지막 줄에 보게 되면 train sample들의 f(x)들을 합하게 된다. f(xi, W)는 데이터 조각들에 대한 밀도함수의 값이라고 할 수 있는데, 이때 f(x), 즉 밀도함수가 최대가 되는 W를 찾는 것이 우리의 목표라고 할 수 있다.

예시로!! 연쇄법칙으로 이전 데이터의 조각을 관찰하고 확률을 계산하게 된 Autoregressive Model이 있다. 이는 직접적으로 확률분포를 모델링하는 것이다.

예시로 PixelRNN과 PixelCNN이 있는데 이들은 p(x)를 직접적으로 계산할 수 있고 좋은 샘플을 얻을 수 있으나 단점은 느리다는 것이다!
이렇게 Variational AutoEncoder이전 내용 끗!! 넘어가서 GAN을 써보겠다 일단 VAE이해하고 옴 ...
이해하고 왔는데 5시간이 지나있네
GAN 공부를 시작해 보겠다...

이는 가우시안과 같은 간단한 prior인 p(z)에서 z를 샘플링하고 이를 generativie network에 넣게 되면 실제 데이터의 분포가 되기를 원하는 방식이다. *여기에서 입력에서의 약간의 변화가 출력에서도 부드러운 변화로 표현 가능하다는 사실이.. 이제 z를 뽑아냈을 때의 벡터 ??근데 얘 랜덤샘플링하잖아 그럼 G(z)를 했을 때 나오는 이미지가?? 부드러운 변화로 표현 가능하다?? -> 생성자가 데이터의 확률분포를 정확히 이해하고 있다 라고..보면 될까..? 분포를 만들어낸다...라.. 그럼 이 분포가 대체 어디에 있는데 가우시안 분포에서 샘플링 된 z가 들어왔을 때 실제 데이터의 분포에 맞는 데이터를 생성해낸다는 말일까?
이때 p(z)는 그냥 노이즈이고, 여기에서 z를 샘플링해서 generator에 넣으면 그냥 이미지가 생성되는 것이다!
그래서 이 모델에는 generator과 discriminator모델이 존재하는데, generator은 pG로부터 x를 샘플링하여 Discriminator이 Pdata에서 샘플링했다고 학습하도록 학습한다. 즉, Discriminator을 속일 만큼 실제 데이터 같은 이미지를 만들어내도록 학습한다.
Discriminator은 생성된 샘플과 실제 샘플 사이에 real과 fake를 구분하도록 학습한다. 이때 최대한 잘 구분하도록 학습하는 것이 중요하다.


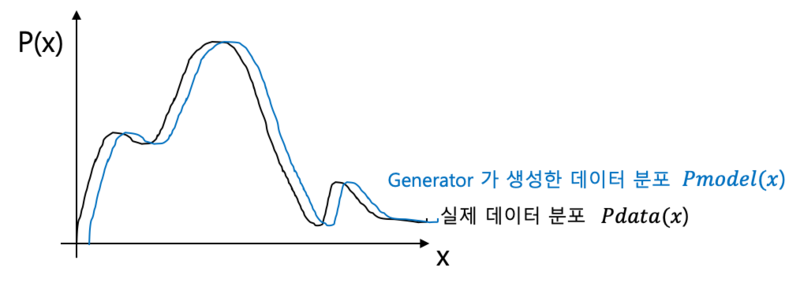
그래서 결론은! generator이 생성한 데이터 분포 p(x)가 실제 데이터 분포에 가까웠으면 좋겠다는 말이다.
이말은 실제 데이터와 비슷한 데이터를 생성하는 generative model을 만들게 된다는 의미이다.

이 두 모델이 서로 경쟁하면서 발전하도록 학습된다. 이 식은 minmax game을 통해 학습하는 과정을 알려준다.
왼쪽은 실제 데이터를 real로 분류하도록 만드는 식인데, discriminator은 이 부분을 1이 되도록 하는 것이 목표이다.
오른쪽은 generator이 생성한 이미지를 discriminator이 진짜냐 가짜냐로 구분하는 부분인데, generator은 true로 인식되길 원하고 discriminator은 0으로 인식되길 원한다.

학습과정인데, Discriminator은 분류 오류를 최소화 하는 것이 목표고 Generator은 최대한 실제와 가까운 데이터를 만들어내는 것이 목표이다. 그런데 여기에서 문제가 discriminator이 너무 잘 판별하면 generator는 이를 속이기 어려워지고, 자체의 손실이 커지게 된다. 이런 상황에서는 Discriminator의 손실은 낮고 Generator의 손실은 높아지게 된다. 이러한 문제가 생기게 되었을 때 불규칙한 loss값이 나오는 그래프가 나올 것이다. 그리고

사용하는 loss는 binary cross entropy!
* 이 때 discriminator을 먼저 학습해야 생성자가 학습 초반에 잘 못만들어 낸다는 것을 잡아낼 수 있겠지?
오른쪽 term에서 log(1−D(G(z)))을 그려보면 파란색 그래프로 이루어졌다. 그런데 학습 초반에는 Generator의 성능이 안좋기 때문에 가 0에 가까울 것인데, 이 때의 그래프를 보면 평평해서 vanishing gradient문제가 발생한다. 그래서
-log(D(G(z)))를 사용하면 초반에 강한 gradient를 얻을 수 있다.

하지만 G와 D는 정해진 NN이므로 Optimal solution으로 이끌지는 모른다. 그리고 서로 성능을 높이려고 하지만 완벽한 균형점에 도달할 지는 모른다. local minima에 빠질 수 있다.
-> mode collapse가 발생한다.
이게 머냐!! 생성자가 다양한 이미지를 만들어 내지 못하고 비슷한 이미지만 계속 생성하는 경우이다. Mode는 최빈값을 말하며 예시로 MNIST 숫자데이터가 있다고 하면 mode는 0~9이고 랜덤노이즈 z를 입력으로 받는 G가 D를 속이기 위해 노이즈를 변환하는데 변환된 데이터의 분포가 특정 숫자에 치우칠때 mode collapse가 발생했다고 한다. generator이 만약에 1의 특징에 가까운 벡터로 변환하여 discriminator을 지속적으로 속일 수 있다면 generator는 노이즈에서 데이터를 잘 생성해냈다는 판단을 내릴 수 있으며, 이는 discriminate가 완벽하지 못하거나 모델이 진동할 때 발생하는 현상이라고 한다.

3에 관련한 이미지만 생성해낸다!!
GAN이 선명한 이유!! 내 뇌피셜은 우선 실제 데이터와 비교해서 뒤지지 않아야 하기 때문에 실제 이미지의 해상도와 비슷한 이미지를 만들어 낼 것 같다. 그냥 그렇다고~
'인공지능' 카테고리의 다른 글
| [코스모스 8주차] Object Detection, Segmentation (0) | 2024.05.09 |
|---|---|
| [코스모스 7주차] Self-Supervised Learning (0) | 2024.05.07 |
| [코스모스 6주차] Activation Function (0) | 2024.04.11 |
| [코스모스 5주차] ATTENTION ~ TRANSFORMER (0) | 2024.04.04 |
| [코스모스 1주차] Variational Auto-Encoders (1) | 2024.03.07 |



